SST OWL Specifics
Together with the ontologies defined in RDF and RDF-S, SST is using the OWL 2 Web Ontology Language / Document Overview as it’s basic foundation. All logical statements from OWL 2 might be used in SST. However there are differences on the impact of these statements that are explained here.
For SST an Ontology corresponds to Dataset in RDF; so every Dataset is an Ontology that can import other ontologies.
OWL 2 is defined for the open-world assumption, meaning there might be facts defined outside of the current Dataset that might heavily impact the semantics of the data defined in this dataset. On the other hand typical database applications are using the so called closed-world assumption; that is, facts that are not defined in the database are not there. SST is based on this closed-world assumption for each dataset. A direct consequence of the closed-world assumption is that any two IBNodes used within the same Dataset in any triple as either subject, predicate or object define two different objects unless it is explicitly stated within the Dataset that they are the same object using owl:sameAs.
SST requires the capabilities of OWL 2 Full, the OWL 2 RDF-Based Semantics. The subset OWL 2 DL, the OWL 2 Direct Semantics that is using a functional-style syntax is not suitable for SST because of the extensive use of Punning; see below. Also the OWL 2 profiles EL, RL and QL are not suitable for SST for the same reasons.
Note that several related standards are based on OWL 2 DL and therefore can’t take advantage of OWL 2 Full including of Punning Individuals with Classes and Properties. These are e.g.:
-
ISO/AWI 23726-100 Automation systems and integration — Ontology based interoperability — Part 100: Schedule data ontology
-
ISO/TS 15926-12:2018 Industrial automation systems and integration — Integration of life-cycle data for process plants including oil and gas production facilities Part 12: Life-cycle integration ontology represented in Web Ontology Language (OWL)
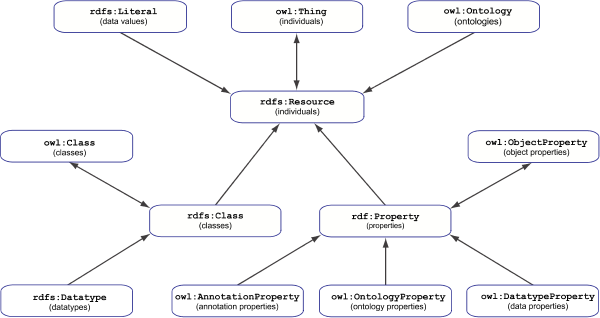
In general, using OWL Full might result in extreme long computation time for reasoning (also called inferencing) on the provided data. This is not the case in SST because of the closed-world assumption (see above) and the requirement to specify for each node basic rdf:type information. With a suitable toolkit such as the SST Core it is possible to process RDF in very high speed.
With the constraints stated here OWL facts can directly be used to validate SST data:
-
SST adopts the “unique names assumption”; this is not the case for OWL
-
for every IBNode a subject-triple with predicate rdf:type and an object of type owl:Class for application data or rdfs:Class for SST ontologies must exist
-
the predicates of all triples must be of rdf:type rdf:Property or one of it’s sub-properties owl:ObjectProperty, owl:DatatypeProperty, owl:OntologyProperty or owl:AnnotationProperty. If the predicate is defined within the Dataset to be validated, then it must in addition be defined to be a rdfs:subPropertyOf one of the properties defined in one of the SST ontologies
-
an owl:FunctionalProperty can be used only once for the subject of a triple; otherwise it is an error
-
an owl:InverseFunctionalProperty can be used only once for the object of a triple; otherwise it is an error
-
the subject of every triple must be explicitly defined to be of the type as defined for the rdfs:domain of the predicate, or an rdfs:subClassOf that type
-
the object of every triples must be of the type as defined for the type as defined for the rdfs:range of the predicate, or an rdfs:subClassOf that type
-
an owl:TransitiveProperty must no be used cyclically
-
… to be extended
There are no articles to list here yet.